

Acelere o processamento de acordo com o seu projeto
As cargas de trabalho de deep learning estão incentivando a inovação no setor de tecnologia em geral e no mercado de processamento em particular. Atualmente, a indústria está pesquisando novas maneiras de calcular cargas de trabalho de deep learning usando processadores projetados especificamente para a execução de redes neurais.
Os FPGAs com CPUs integradas de vários núcleos oferecem flexibilidade e desempenho para executar cargas de trabalho de deep learning, onde, quando e como o maior rendimento pode ser alcançado. Eles também oferecem um caminho de migração para demandas futuras, seja em inteligência artificial, redes de próxima geração ou qualquer segmento que possa ser tratado pela HPC (computação de alto desempenho).
Novos FPGAs proporcionam aumento de desempenho e flexibilidade de integração
Os FPGAs Intel® Stratix® 10 oferecem um caminho para o desempenho acelerado do deep learning e a integração simples com os sistemas implantados. Esses FPGAs integram até 5,5 milhões de elementos lógicos, além de uma CPU Arm Cortex-A53 de 64 bits e quatro núcleos. Eles também fornecem pinos de I/O programáveis que permitem aos FPGAs interagir facilmente com as tecnologias de rede e computação padrão.
Em relação ao desempenho, os dispositivos Intel Stratix 10 foram projetados usando a nova arquitetura FPGA Intel® HyperFlex ™. Essa arquitetura introduz a tecnologia de Hyper-Registers, que coloca registros ignoráveis em todos os segmentos de roteamento do núcleo do dispositivo e em todas as entradas de blocos funcionais (Figura 1).
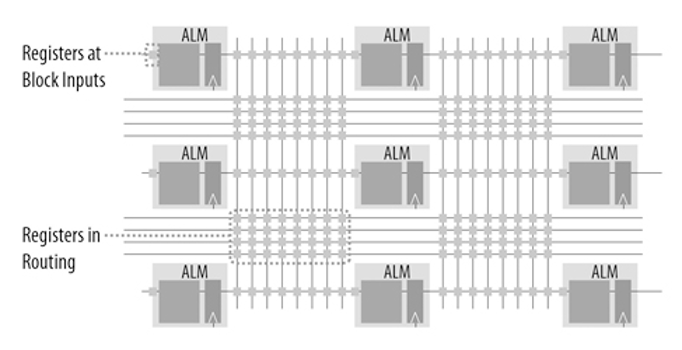
Figura 1. Os Hyper-Registers colocam registros em todos os segmentos de roteamento e em todas as entradas de blocos funcionais para permitir a duplicação da frequência do relógio. (Fonte: Intel® Corporation)
Os registradores ignoráveis otimizam o fluxo de dados através da malha FPGA, o que ajuda os chips a alcançar o desempenho máximo. Como resultado, os dispositivos Intel Stratix 10 oferecem o dobro da velocidade de clock dos FPGAs da geração anterior, com um consumo de energia 70% menor. Essa conquista notável torna os FPGAs adequados para aplicativos que exigem muito desempenho, mas com restrição de energia.
Em termos de integração de plataforma, os dispositivos Intel Stratix 10 FPGA suportam interfaces flash serial e paralela. Esses tipos de memória – comuns em plataformas de rede – têm grande utilidade para deep learning, pois permitem que os desenvolvedores escolham uma configuração que melhor se adapte à sua carga de trabalho. A placa PCIe DE10-Pro Stratix 10 GX / SX da Terasic Inc., por exemplo, suporta vários tipos de memória para várias aplicações (Figura 2):
- Módulo de memória QDR-IV para aplicativos de alta largura de banda e baixa latência
- Módulo de memória QDR-II + para leitura / gravação de memória de baixa latência
- DDR4 para aplicativos que exigem a maior capacidade de memória possível

Figura 2. A placa PCIe DE10-Pro Stratix 10 GX / SX da Terasic, Inc. suporta vários tipos de memória para diferentes casos de uso de deep learning.
A DE10-Pro inclui faixas PCIe Gen 3 x16 para velocidades de transferência de dados chip a chip de até 128 Gbps, enquanto quatro conectores QSFP28 suportam 100 Gigabit Ethernet. Essas interfaces permitem enormes recursos de transferência de dados, bem como, acesso rápido à memória de leitura e gravação. Em ambientes de servidor ou datacenter, isso significa que as cargas de trabalho podem ser compartilhadas entre bancos de recursos de computação e memória para dimensionar o desempenho do aprendizado profundo, conforme necessário.
Por fim, da perspectiva do software, a placa PCIe DE10-Pro Stratix 10 GX / SX suporta o kit de ferramentas Intel® Open Visual Inference e Otimização de rede neural (Intel® OpenVINO ™). O OpenVINO é um conjunto de desenvolvimento para arquiteturas de execução heterogêneas, baseado em uma API comum que abstrai a complexidade da programação FPGA.
O OpenVINO inclui uma biblioteca de funções, kernels e chamadas otimizadas para OpenCV e OpenVX, e demonstrou aprimoramentos de desempenho de até 19x para visão computacional e cargas de trabalho de deep learning (Figura 3).
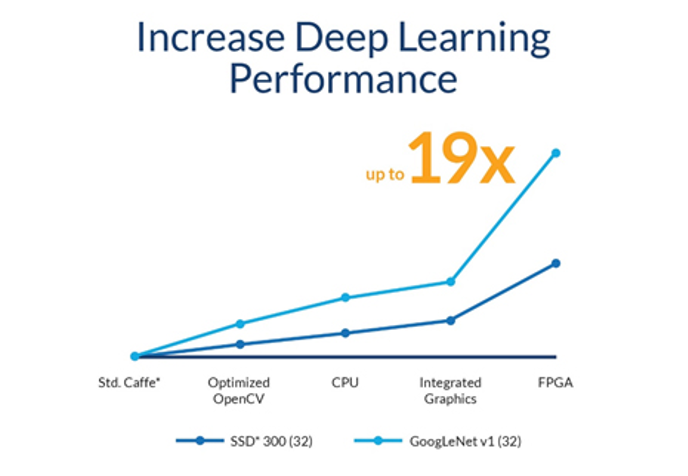
Figura 3. O kit de ferramentas Inferência Visual Aberta e Otimização de Rede Neural (OpenVINO ™) demonstrou otimizações significativas de desempenho. (Fonte: Intel® Corporation)
Saiba mais Aqui



